Apendizaje profundo, una introducción
https://rubenlopezg.wordpress.com/2014/05/07/que-es-y-como-funciona-deep-learning/
¿Qué es y cómo funciona “Deep Learning”?
Publicado el May 7, 2014
por Rubén L.
 Deep Learning es el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
Deep Learning es el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
 Deep Learning es el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
Deep Learning es el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
Voy a comenzar el artículo presentando las redes de neuronas y su entrenamiento, y a continuación cómo se pueden utilizar para realizar Deep Learning. Si ya estás familiarizado con las redes de neuronas, puedes saltar directamente a la sección de auto-codificadores.


Redes de neuronas
Aunque existen varias maneras de implementar Deep Learning, una de las más comunes es utilizar redes de neuronas. Una red de neuronas es una herramienta matemática que modela, de forma muy simplificada, el funcionamiento de las neuronas en el cerebro. Dicho así suena bastante complicado, pero en realidad es una serie de operaciones matemáticas sobre una lista de números, que da como resultado otra lista de números. Otra forma de verlas, es como un procesador de información, que recibe información entrante, codificada como números, hace un poco de magia, y produce como resultado información saliente, codificada como otros números.
Un ejemplo concreto sería una red de neuronas que detecte rostros en imágenes. Es muy fácil codificar una imagen como una lista de números. De hecho, ya las codificamos así en los ordenadores. Por tanto, esta red recibiría tantos números a su entrada como píxeles tienen nuestras imágenes (o tres por cada píxel si utilizamos imágenes en color). Y si la información que esperamos a la salida es que nos diga si hay un rostro o no, basta con un solo número. en la lista saliente. Podemos imaginar que si ese número, que sale de la red, toma un valor cercano a 1.0 significa que hay un rostro, y si toma un valor cercano a 0.0 significa que no lo hay. Valores intermedios se pueden interpretar como inseguridad, o probabilidad.
Arquitectura
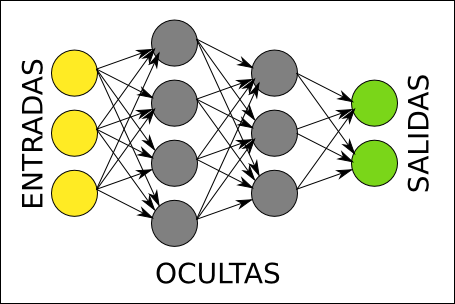
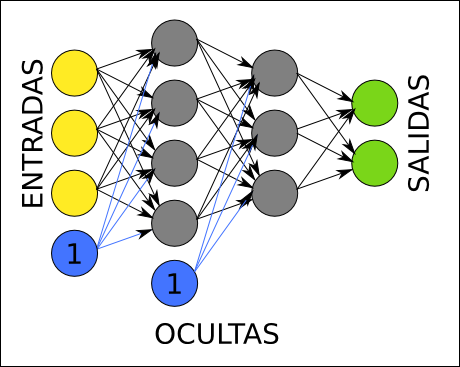
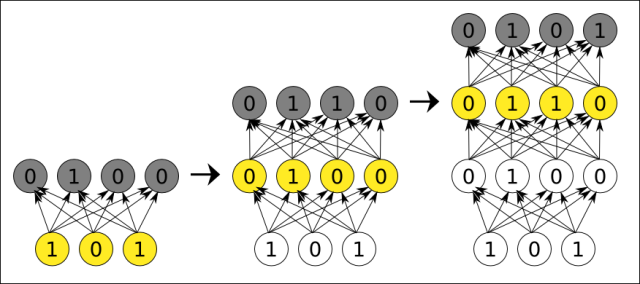
En el siguiente diagrama podemos ver la arquitectura de una red de neuronas. Cada círculo representa una neurona. Las neuronas se organizan en capas, de la siguiente forma: las neuronas amarillas son las entradas, y reciben cada uno de los números de nuestra lista de números entrante, las neuronas verdes son las salidas, y una vez que la red realiza su operación matemática, contienen el resultado, también como una lista de números; las neuronas grises son neuronas ocultas, que contienen cálculos intermedios de la red.

Arquitectura de una red de neuronas.
Normalmente todas las neuronas de cada capa tienen una conexión con cada neurona de la siguiente capa, como se representa en el diagrama. Estas conexiones tienen asociado un número, que se llama peso. La principal operación que realiza la red de neuronas consiste en multiplicar los valores de una neurona por los pesos de sus conexiones salientes. Cada neurona de la siguiente capa recibe números de varias conexiones entrantes, y lo primero que hace es sumarlos todos.
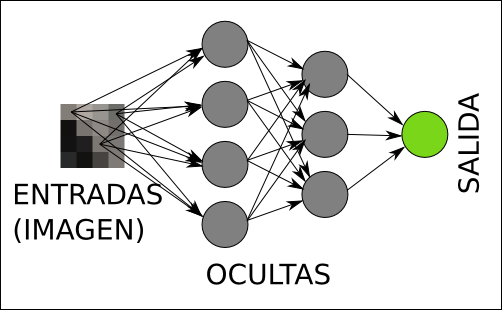
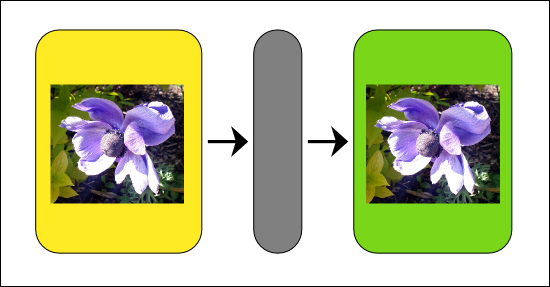
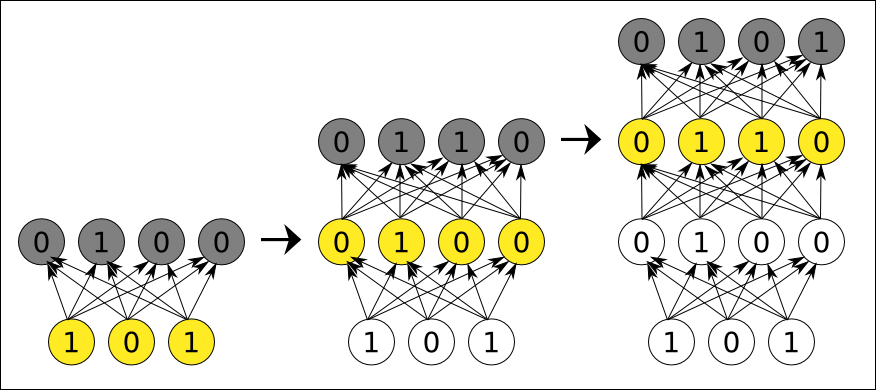
Continuando con el ejemplo anterior, la arquitectura de la red que detecta rostros en una imagen, tendría un aspecto similar al siguiente (sólo se dibujan las conexiones desde tres píxeles para no liar el gráfico):

Arquitectura de la red de neuronas para detectar elementos en una imagen.
Función de activación
Hasta el momento, la operación de la red de neuronas es sencilla, se trata de productos y sumas. Hay otra operación que realizan todas las capas salvo la capa de entrada, antes de continuar multiplicando sus valores por las conexiones salientes, se trata de la función de activación. Esta función recibe como entrada la suma de todos los números que llegan por las conexiones entrantes, transforma el valor mediante una fórmula, y produce un nuevo número. Existen varias opciones, pero una de las funciones más habituales es la función sigmoide. Uno de los objetivos de la función de activación es mantener los números producidos por cada neurona dentro de un rango razonable (por ejemplo, números reales entre 0 y 1).
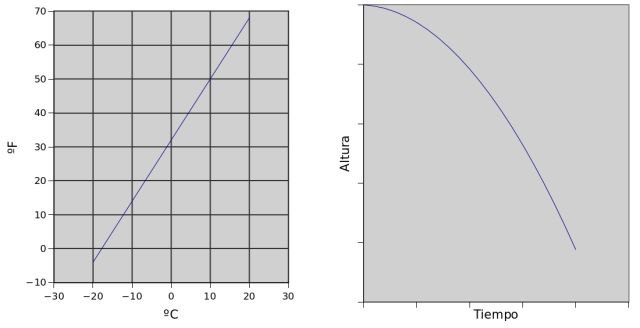
La función sigmoide es no lineal, esto significa que si dibujamos en una gráfica los valores de entrada en un eje y los de salida en el otro eje, el dibujo no será una línea. Esto es muy importante, porque si la función de activación que elegimos es lineal, la red estará limitada a resolver problemas lineales (muy simples).
Un ejemplo de problema lineal sería la conversión de temperatura entre Celsius (Europa) y Fahrenheit (EEUU). Si dibujamos uno frente a otro en una gráfica, el resultado será una línea.

Transformación lineal (izquierda) frente a no lineal (derecha).
Un ejemplo de problema no lineal es la posición vertical de una manzana cayendo con respecto al tiempo. Si dibujamos la posición de la manzana en un eje, y el tiempo en otro, la gráfica será una curva, debido a la aceleración de la gravedad.
Implementación
Una forma sencilla de implementar redes de neuronas consiste en almacenar los pesos en matrices. Es fácil ver que si ahora guardamos los valores de todas las neuronas de una capa en un vector, el producto del vector y la matriz de pesos de salida, nos da los valores de entrada de cada neurona en la siguiente capa. Ahora sólo falta aplicar la función de activación que hayamos elegido a cada elemento de ese segundo vector, y repetir el proceso. Si disponemos de una biblioteca que implemente matrices, se puede implementar la red en unas pocas líneas.
Ya existen muchas librerías de código abierto que implementan redes de neuronas, comolibfann.
Bias
Justo antes de aplicar la función de activación, cada neurona añade a la suma de productos un nuevo término constante, llamado habitualmente bias. Una forma típica de implementar este término consiste en imaginarse que extendemos la capa anterior con una falsa neurona que siempre toma como valor un 1.0, e incorporar los pesos correspondientes a dicha falsa neurona a la matriz de pesos.

Red de neuronas con bias (los valores de bias se representan como conexiones azules).
Para ver su importancia con un ejemplo muy sencillo, imaginémonos una función de activación lineal (no hacer nada), y sólo dos neuronas en la red (una en la capa de entrada, y otra en la capa de salida). Tal como hemos explicado antes, esta red se limita a hacer una multiplicación y nada más. Si queremos usar esta red para convertir entre Celsius y Fahrenheit, tenemos un problema, porque a 0ºC le corresponden 32ºF, y sólo con una multiplicación no podemos hacer esto. Sin embargo, al introducir el término Bias, tenemos una multiplicación y luego una suma, con lo cual ya podríamos hacer el conversor de ºC a ºF.
Otras arquitecturas
Sin entrar en detalles, es interesante saber que existen arquitecturas de redes de neuronas diferentes que también se usan en ocasiones para implementar Deep Learning.
Por ejemplo, las redes de neuronas recurrentes no tienen una estructura de capas, sino que permiten conexiones arbitrarias entre todas las neuronas, incluso creando ciclos. Esto permite incorporar a la red el concepto de temporalidad, y permite que la red tenga memoria, porque los números que introducimos en un momento dado en las neuronas de entrada, son transformados y continúan circulando por la red incluso después de cambiar los números de entrada por otros diferentes.
Otra arquitectura interesante son las redes de neuronas convolutivas (Convolutional neural networks). En este caso se mantiene el concepto de capas, pero cada neurona de una capa no recibe conexiones entrantes de todas las neuronas de la capa anterior, sino sólo de algunas. Esto favorece que una neurona se especialice en una región de la lista de números de la capa anterior, y reduce drásticamente el número de pesos y de multiplicaciones necesarias. Lo habitual es que dos neuronas consecutivas de una capa intermedia se especialicen en regiones solapadas de la capa anterior. Quienes conozcan el concepto de convolución, entenderán de dónde sale el nombre.
Aprendizaje en redes de neuronas
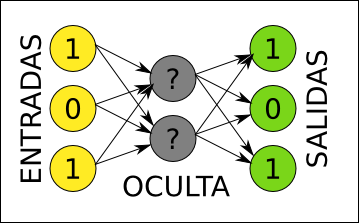
Supongamos que ya tenemos claro cuantas neuronas nos hacen falta a la entrada y a la salida, porque ya hemos decidido cómo representar nuestra información en forma de listas de números. Todavía nos faltan varias cosas por decidir para tener una red que funcione:
- Cuántas capas ocultas vamos a incluir.
- Cuántas neuronas vamos a poner en cada capa oculta.
- Qué pesos concretos usaremos en las conexiones entre cada par de capas.
Habitualmente los dos primeros puntos se deciden a mano, y algunas veces mediante prueba y error. Lógicamente, cuantas más neuronas tengamos en capas ocultas, más compleja es la red, y podrá resolver a su vez problemas más complejos. Por otra parte, cuantas más neuronas ocultas tengamos, más costará realizar todos los productos y sumas.
Es importante mencionar que si hemos elegido una función de activación lineal, no merece la pena utilizar capas ocultas en absoluto, porque se puede comprobar que la potencia de la red será la misma por muchas capas que pongamos. La potencia de la red sólo aumenta con el número de capas para funciones de activación no lineales, como la sigmoide.
El tercer punto, afortunadamente, se puede resolver de forma automática, mediante un proceso llamado entrenamiento. Para entrenar una red de neuronas, necesitamos primero recopilar algunos ejemplos de entradas y la salida que deseamos para cada ejemplo. Por ejemplo, en el detector de rostros, necesitamos recopilar ejemplos de imágenes con rostros, y ejemplos de imágenes sin rostros. También necesitamos etiquetar cuales son las imágenes que tienen rostros y cuales las que no, porque esa es precisamente la salida deseada para cada ejemplo. Este proceso de entrenamiento se conoce como aprendizaje supervisado, porque el sistema necesita de un supervisor que le explique lo que tiene que hacer (mediante ejemplos de entradas y salidas).
Propagación hacia atrás (backpropagation)
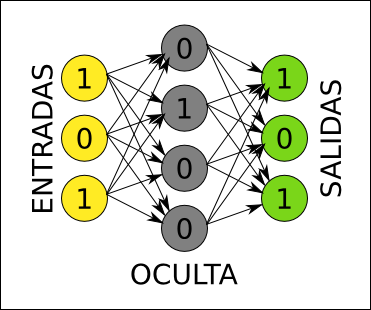
Una vez que tenemos un conjunto de ejemplos, es muy fácil evaluar la red con cada ejemplo y comprobar el error entre la salida deseada y la salida que está produciendo la red. Para calcular el error, en cada neurona de la capa de salida, restamos el valor producido y el que esperábamos que se produjese. Sabiendo cual es el error para un determinado ejemplo, podemos intentar corregirlo.
La idea para corregir errores consiste en buscar culpables. Entre las neuronas de salida es fácil saber quienes son las culpables: sabemos exactamente cuánto error se produce en cada neurona, tal como se explicó antes. Pero cada una de esas neuronas está conectada con las neuronas anteriores mediante unos pesos. Podemos usar esos pesos para determinar cuanto contribuyen las neuronas anteriores al error, simplemente propagando los errores hacia atrás del mismo modo que propagamos valores hacia delante, multiplicando y sumando. De este modo, podemos saber cuanto contribuye al error cada neurona de toda la red.
Sabiendo cuanto contribuye cada neurona al error, podemos intentar actualizar los pesos para reducir ese error. Primero necesitamos averiguar cómo afectan al error los cambios producidos a los pesos. Dicho de otra forma, necesitamos determinar la velocidad con que cambia el error con respecto a los pesos. Sabiendo esto, el siguiente paso consiste en cambiar los pesos en la medida justa para que el error se reduzca a la mayor velocidad posible.
La velocidad con que cambia el error con respecto a los pesos se calcula con derivadas parciales, e implica que debemos ser capaces de derivar la función de activación. No quiero entrar en detalles matemáticos, tenéis una explicación detallada en el artículo de wikipedia sobre propagación hacia atrás, por si queréis programar vuestra propia red de neuronas con aprendizaje. La biblioteca libfann mencionada anteriormente incluye este algoritmo e incluso algunas variaciones.
¿Y cómo empezamos el proceso? Pues con pesos generados al azar. Más adelante veremos alguna alternativa.
Al utilizar una librería de redes de neuronas existente, lo más habitual es que al entrenar obtengamos información de cómo va el proceso en forma de error cuadrático medio (MSE). La idea es que para cada ejemplo que tenemos, la red evalúa el error en todas sus neuronas de salida tal como indicamos antes, eleva cada uno de esos números al cuadrado, y finalmente calcula el promedio. Al elevar cada error al cuadrado, los errores siempre son positivos, así que los errores de unas neuronas no anulan a los de otras. Es importante recordar que no se trata de un porcentaje. Para decidir cual es el error mínimo a partir del cual podemos parar de entrenar, una forma sencilla es decidir el máximo error que estamos dispuestos aceptar para cada neurona de salida, calcular los cuadrados y luego la media.
Límites de la propagación hacia atrás
Un grave problema de los algoritmos de propagación hacia atrás es que el error se va diluyendo de forma exponencial a medida que atraviesa capas en su camino hasta el principio de la red. Esto es un problema porque en una red muy profunda (con muchas capas ocultas), sólo las últimas capas se entrenan, mientras que las primeras apenas sufren cambios. Por eso a veces compensa utilizar redes con pocas capas ocultas que contengan muchas neuronas, en lugar de redes con muchas capas ocultas que contengan pocas neuronas. Esto era así hasta que Deep Learning se puso de moda, como veremos más adelante.
Auto-codificadores (autoencoders)
Otra de las herramientas utilizadas habitualmente para implementar Deep Learning son los auto-codificadores (autoencoders). Normalmente se implementan como redes de neuronas con tres capas (sólo una capa oculta).
Un auto-codificador aprende a producir a la salida exactamente la misma información que recibe a la entrada. Por eso, las capas de entrada y salida siempre deben tener el mismo número de neuronas. Por ejemplo, si la capa de entrada recibe los píxeles de una imagen, esperamos que la red aprenda a producir en su capa de salida exactamente la misma imagen que le hemos introducido. A primera vista parece un artilugio bastante inútil, básicamente no hace nada.

Ejemplo de auto-codificador de imágenes. Cada caja representa una capa de neuronas.
La clave está en la capa oculta. Imaginémonos por un momento un auto-codificador que tiene menos neuronas en la capa oculta que en las capas de entrada y salida. Dado que exigimos a esta red que produzca a la salida el mismo resultado que recibe a la entrada, y la información tiene que pasar por la capa oculta, la red se verá obligada a encontrar una representación intermedia de la información en su capa oculta usando menos números. Por tanto, al aplicar unos valores de entrada, la capa oculta tendrá una versión comprimida de la información, pero además será una versión comprimida que se puede volver a descomprimir para recuperar la versión original a la salida.

Ejemplo de auto-codificador.
De hecho, una vez entrenada, se puede dividir la red en dos, una primera red que utiliza la capa oculta como capa de salida, y una segunda red que utiliza esa capa oculta como capa de entrada. La primera red sería un compresor, y la segunda un descompresor.
Precisamente por eso, este tipo de redes se denominan auto-codificadores, son capaces de descubrir por si mismos una forma alternativa de codificar la información en su capa oculta. Y lo mejor de todo es que no necesitan a un supervisor que les muestre ejemplos de cómo codificar información, se buscan la vida ellas solas. Por eso se suele decir que se trata de aprendizaje no supervisado.
Auto-codificadores dispersos
El ejemplo de red que comprime información es interesante, pero no es el uso más habitual de estas redes en Deep Learning. ¿Qué pasaría si la capa oculta, en lugar de tener menos neuronas, tuviese más que las capas de entrada y salida? Existe un riesgo, y es que la red no aprenda nada: que se limite a copiar la entrada a un subconjunto de las neuronas en la capa oculta (dejando las neuronas sobrantes sin usar), y luego las vuelva a copiar a la salida. Pero ¿y si pudiésemos forzar que las neuronas de la capa oculta se activen pocas veces? Entonces la red tendría que aprender nuevamente un código alternativo, y además, disperso.

Ejemplo de auto-codificador disperso.
La idea del código disperso es que los valores en las neuronas de la capa oculta sean 0 la mayor parte de las veces. Para cada ejemplo, sólo unas pocas neuronas tendrían un valor alto, y las demás estarían cerca de 0. En la imagen anterior, el ejemplo de entrada [1, 0, 1] se representa en la capa oculta mediante los valores [0, 1, 0, 0]. Sólo una neurona se activa. Al introducir una restricción de dispersión, la capa oculta no puede representar tantas combinaciones de valores como podría representar si no tuviese esa restricción. Por ejemplo, nunca podrá tomar los valores [1, 1, 1, 1]. Esto limita mucho la expresividad de la capa oculta, pero a cambio obliga a que cada neurona de esa capa se especialice en un cierto patrón en la entrada.
Hay varias formas de conseguir que la red no se limite a copiar la información sin más cuando la capa oculta tiene neuronas de sobra (se pueden incluso combinar):
- Añadir, a la hora de calcular el error, un factor de dispersión. Si la dispersión es baja, añadiría mucho error, y si es alta, poco error. No es muy complicado de hacer, simplemente debemos buscar una fórmula que podamos diferenciar, para poder actualizar los pesos. Muchas bibliotecas de redes de neuronas no tienen esta funcionalidad, así que necesitaríamos implementar la nuestra. La mayor dificultad radica en encontrar el factor de dispersión adecuado para nuestro problema, ya que diferentes factores cambian significativamente el rendimiento del auto-codificador.
- Al componer los ejemplos, en lugar de indicar el mismo valor para las entradas y las salidas, introducir un poco de ruido en el vector de entrada, y dejar el de salida sin ruido. De esta forma, la red está forzada a generalizar, porque tendrá varios ejemplos ligeramente diferentes de entrada que producen la misma salida. La representación intermedia en la capa oculta tendrá que enfocarse en las características comunes de todas las versiones de la misma imagen con diferentes ruidos. Una ventaja de este método es que multiplicamos los ejemplos que tenemos, porque podemos usar el mismo ejemplo varias veces con distintos ruidos. Además podemos usar cualquier biblioteca de redes de neuronas ya existente.
En ambos casos la red está forzada a generalizar, y encontrar patrones en los ejemplos que pueda representar mediante las neuronas de su capa oculta. Estos patrones son características frecuentes en los ejemplos. De hecho, es muy sencillo descubrir cual es la información de entrada que provoca una activación total en una de las neuronas de la capa oculta, o lo que es lo mismo, qué característica representa cada una de estas neuronas: basta con resolver una ecuación.
Para ver un ejemplo concreto, imaginémonos que utilizamos las imágenes de dígitos escritos a mano de la base de datos MNIST. Esta base de datos contiene dígitos como los mostrados a continuación:

Ejemplo de dígitos escritos a mano.
Para entrenar un auto-codificador, supongamos que recortamos parches de 8×8 píxeles de esta base de datos, y configuremos el auto-codificador con 100 neuronas en su capa oculta. Tal como se explicó, mostraremos a la red el mismo parche a la entrada y la salida, y la red aprenderá una codificación intermedia. Ahora, si dibujamos el parche que activa completamente cada una de las 100 neuronas de la capa oculta, obtendremos el siguiente gráfico (los 100 patrones se han distribuido en una matriz 10×10 por comodidad):

Patrones que activan cada una de las 100 neuronas de un auto-codificador.
Como se puede apreciar en la imagen, los parches que activan al máximo cada neurona de la capa oculta representan características fundamentales de los dígitos, como esquinas, líneas con distintos ángulos, algunas curvas, e incluso algunos círculos (probablemente para los ochos).
Para entrenar el auto-codificador se utilizó solamente la técnica de añadir ruido en la entrada, concretamente píxeles negros con una probabilidad del 20%.
Como os podéis imaginar, una vez entrenado un auto-codificador, la segunda mitad de la red se puede descartar, normalmente nos interesa sólo la parte que codifica.
Apilando auto-codificadores
Un solo auto-codificador puede encontrar características fundamentales en la información de entrada, las características más primitivas y simples que se pueden extraer de esa información, como rectas y curvas en el caso de las imágenes. Sin embargo, si queremos que nuestras máquinas detecten conceptos más complejos como rostros, nos hace falta más potencia.
Fijémonos en la operación que realiza un auto-codificador en su capa oculta. A partir de información cruda sin significado (por ejemplo, píxeles de imágenes), es capaz de etiquetar características algo más complejas (por ejemplo, formas simples presentes en cualquier imagen como líneas y curvas). Entonces la pregunta es, ¿qué pasa si al resultado codificado, en esa capa oculta, le aplicamos otro auto-codificador? Si lo hacemos bien, encontrará características más complejas todavía (como círculos, arcos, ángulos rectos, etc). Si continuamos haciendo esto varias veces, tendremos una jerarquía de características cada vez más complejas, junto con una pila de codificadores. Siguiendo el ejemplo de las imágenes, dada una profundidad suficiente e imágenes de ejemplo suficientes, conseguiremos alguna neurona que se active cuando la imagen tenga un rostro, y sin necesidad de que ningún supervisor le explique a la red cómo es un rostro.
La idea de Deep Learning mediante auto-codificadores apilados es precisamente esa, usar varios codificadores, y entrenarlos uno a uno, usando cada codificador entrenado para entrenar el siguiente. Podríamos llamarlo un algoritmo voraz (greedy), y éste es realmente el gran avance del Deep Learning que permite hacer todas esas cosas tan fantásticas que leemos últimamente.
Auto codificadores apilados.
Una red profunda creada de este modo tiene dos características muy importantes:
- Aprende sin supervisión, sólo necesita datos y encuentra ella sola características frecuentes con las que etiquetar los datos.
- Podemos entrenar redes todo lo profundas que queramos. Tal como se comentó en la sección de propagación hacia atrás, al entrenar redes muy profundas teníamos un problema porque el error se va diluyendo y las primeras capas casi no se entrenan. Aquí no tenemos ese problema.
Incluso existen teorías sobre el desarrollo del cerebro humano que plantean la posibilidad de que también tenga aprendizaje secuencial por capas.
Convolución y pooling
En el ejemplo anterior sobre los dígitos escritos a mano, usamos parches de imagen de 8×8 píxeles para entrenar un auto-codificador. La pregunta es, ¿por qué no introducir las imágenes completas?
- Cuanto mayor es la entrada del auto-codificador, más pesos hay que entrenar, y más lento es todo el proceso de entrenamiento. Si tenemos imágenes de 1000×1000 pixeles, y utilizamos 1000 neuronas en la capa oculta, necesitaríamos entrenar 2000 millones de pesos, mientras que si utilizamos parches de 8×8 y utilizamos 100 neuronas en la capa oculta, entrenamos sólo 12800 pesos.
- Si usamos imágenes enteras, para el auto-codificador una imagen que tenga un rostro centrado, y otra que tenga el mismo rostro ligeramente desplazado hacia un lado, son completamente diferentes.
Especialmente con el fin de resolver el segundo punto, se puede utilizar una técnica conocida como convolución, y que está basada en cómo se estructuran realmente las neuronas en nuestro sistema visual.
La idea de base es, ¿qué más da dónde aparezca un círculo? Un círculo sigue siendo un círculo aunque lo desplacemos.
Por eso, podemos entrenar un auto-codificador con parches de imagen, y luego desplazar el codificador por toda la imagen, como si fuese un escáner, buscando características. Este proceso transforma la matriz de píxeles en otra matriz de características (listas de números) producidas por el codificador. Es esencialmente la misma imagen, pero cada pixel es mucho más rico en información, y contiene información de la región en que se encuentra el pixel, no sólo del pixel aislado.

Ejemplo de convolución con una ventana de 2×2.
El siguiente paso, llamado pooling, consiste en agrupar las características (listas de números) de varias coordinadas contiguas de la imagen, con alguna función de agrupación (la media, o el máximo). Esta etapa reduce la resolución de la imagen. A continuación podemos continuar haciendo convolución y pooling hasta que nos quede una imagen de 1×1 pixeles con muchísima información, o podemos incluir auto-codificadores intermedios que procesen los datos para buscar características de más alto nivel.

Ejemplo de pooling con una ventana de 2×2 y calculando el promedio.
En una sola etapa de convolución y pooling, obtenemos una imagen de menos resolución, y que en cada píxel nos cuenta la siguiente historia: “en esta región de la imagen hay un círculo y una línea”. No nos dice exactamente dónde estaba el círculo en la matriz con la resolución original. Si ahora acoplamos otro auto-codificador, alguna neurona puede aprender a activarse siempre que reciba esta información agregada acerca de un círculo y una línea, y cuando apliquemos todo el sistema a nuestros números, esa neurona se activará cuando la imagen tenga dibujado el número nueve, por ejemplo.
Aprendizaje supervisado y Deep Learning
¿Qué pasa si realmente necesitamos realizar aprendizaje supervisado? Por ejemplo, quizás no nos vale con que la red vea vídeos de YouTube y descubra por si sola el concepto de gato, sino que queremos que aprenda a etiquetar objetos concretos que nos interesan.
Dado que todos esos codificadores compuestos son una red de neuronas convencional, podemos continuar con un entrenamiento supervisado convencional (propagación hacia atrás).
Al usar propagación hacia atrás, volvemos al problema del error que se diluye y, por tanto, las primeras capas van a sufrir un menor entrenamiento que las últimas. Pero precisamente las primeras capas son las que menos cambios necesitan, porque se enfocan en características fundamentales (de muy bajo nivel) necesarias para detectar cualquier objeto complejo. Cuanto más cerca está una capa de la salida, más nos interesa que sufra cambios en el entrenamiento supervisado y se enfoque en detectar los objetos complejos que a nosotros nos interesan.
Por eso, una técnica muy habitual en Deep Learning consiste en entrenar de manera no supervisada una pila de auto-codificadores, y a continuación, componer los codificadores y continuar con un entrenamiento supervisado. Es decir, el entrenamiento supervisado, en lugar de empezar con pesos al azar, empieza con pesos útiles, especialmente para las primeras capas.
Habitualmente es mucho más fácil encontrar información sin etiquetar (para la cual no tenemos una “salida deseada”) que información etiquetada. Y de repente, toda esa información sin etiquetar resulta útil para la fase de entrenamiento no supervisado. En el ejemplo de los rostros en imágenes, podríamos usar todas las imágenes que encontremos por Internet para entrenar la pila de auto-codificadores, y luego unas pocas que manualmente hayamos etiquetado para refinar y que la red se fije simplemente en si hay o no rostros.
Alternativas
Los auto-codificadores no son el único mecanismo para realizar Deep Learning. Existen otras alternativas, como las Deep Belief Networks. Estas consisten también en una serie de capas entrenadas una a una, de la más específica a la más genérica, pero cada capa en lugar de un auto-codificador, utiliza una Restricted Boltzmann Machine. La idea general es la misma, sólo cambian algunos ladrillos.
Referencias
Deep learning se basa fundamentalmente en un montón de técnicas que ya existían con anterioridad. Algunas de estas técnicas son algo complejas, como el entrenamiento en redes de neuronas, pero existen un montón bibliotecas para múltiples lenguajes de programación que las implementan por vosotros. El gran avance ha sido la manera de combinarlas, especialmente el uso de auto-codificadores apilados que se entrenan capa a capa para lograr aprendizaje no supervisado eficiente.
A continuación os dejo una serie de referencias útiles si queréis implementar todas estas técnicas:
- Propagación hacia atrás (estándar).
- El algoritmo RPROP, una versión rapidísima del algoritmo de propagación hacia atrás. Muy recomendable si implementáis vuestra propia red de neuronas.
- FANN, una biblioteca de redes de neuronas que implementa tanto la propagación hacia atrás estándar como RPROP.
- Cómo visualizar un auto-encoder entrenado, con la fórmula que debemos aplicar, y un ejemplo de visualización.
- Técnicas para visualizar redes convolucionales, con ideas para reconstruir nuestra imagen original tras pasarla por una etapa de convolución+pooling.
- Tutorial sobre Deep Learning en inglés.
- Restricted Boltzmann Machines: Todas las fórmulas matemáticas que necesitáis para implementar esta alternativa a los auto-codificadores.
- Base de datos MNIST, con 60000 imágenes de dígitos escritos a mano, y las etiquetas indicando el dígito al que corresponde cada imagen.
- Base de datos CIFAR-10, con 60000 imágenes de objetos en color, clasificadas en 10 tipos diferentes de objeto.
- deeplearning.net, un portal en inglés con infinidad de recursos sobre deep learning.
Gracias a Silvia Izquierdo y Alberto Jaspe por revisar este artículo.



Comentarios
Publicar un comentario